A probabilistic molecular fingerprint for big data settings
The paper A probabilistic molecular fingerprint for big data settings has been published by the Journal of Cheminformatics.
Background
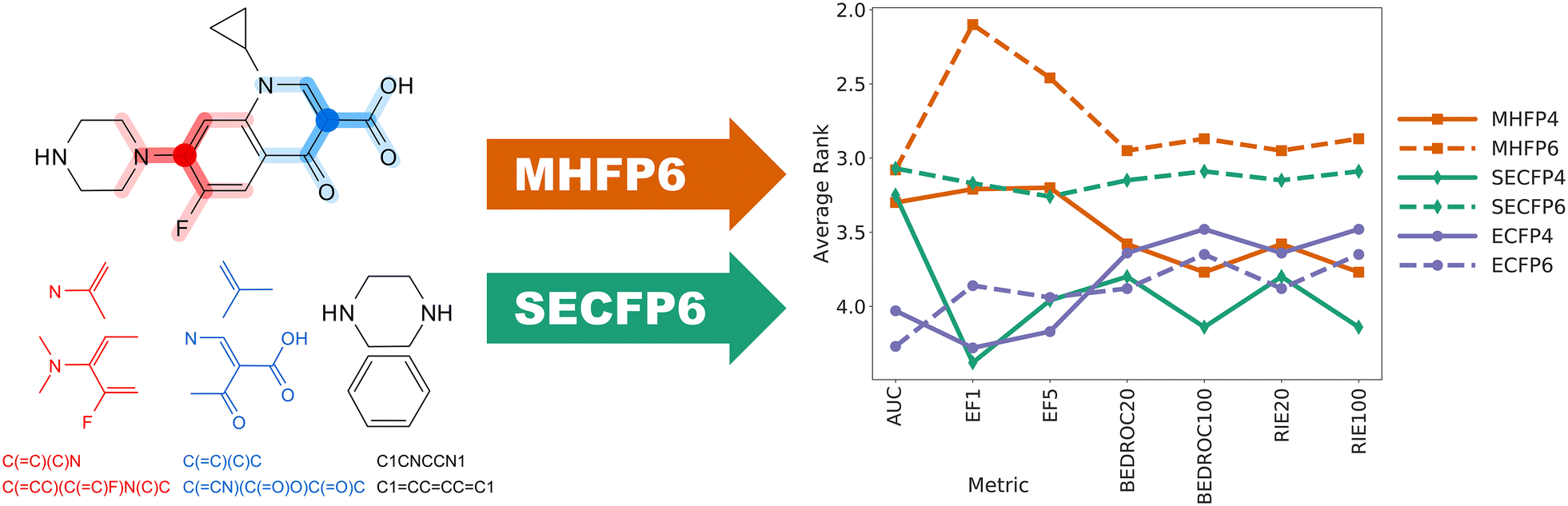
Among the various molecular fingerprints available to describe small organic molecules, extended connectivity fingerprint, up to four bonds (ECFP4) performs best in benchmarking drug analog recovery studies as it encodes substructures with a high level of detail. Unfortunately, ECFP4 requires high dimensional representations (≥ 1024D) to perform well, resulting in ECFP4 nearest neighbor searches in very large databases such as GDB, PubChem or ZINC to perform very slowly due to the curse of dimensionality.
Results
Herein we report a new fingerprint, called MinHash fingerprint, up to six bonds (MHFP6), which encodes detailed substructures using the extended connectivity principle of ECFP in a fundamentally different manner, increasing the performance of exact nearest neighbor searches in benchmarking studies and enabling the application of locality sensitive hashing (LSH) approximate nearest neighbor search algorithms. To describe a molecule, MHFP6 extracts the SMILES of all circular substructures around each atom up to a diameter of six bonds and applies the MinHash method to the resulting set. MHFP6 outperforms ECFP4 in benchmarking analog recovery studies. By leveraging locality sensitive hashing, LSH approximate nearest neighbor search methods perform as well on unfolded MHFP6 as comparable methods do on folded ECFP4 fingerprints in terms of speed and relative recovery rate, while operating in very sparse and high-dimensional binary chemical space.
Conclusion
MHFP6 is a new molecular fingerprint, encoding circular substructures, which outperforms ECFP4 for analog searches while allowing the direct application of locality sensitive hashing algorithms. It should be well suited for the analysis of large databases. The source code for MHFP6 is available on GitHub (https://github.com/reymond-group/mhfp).
Author(s): Daniel Probst and Jean-Louis Reymond