Visualization of Very Large High-Dimensional Data Sets as Minimum Spanning Trees
The preprint Visualization of Very Large High-Dimensional Data Sets as Minimum Spanning Trees has been posted to ChemRxiv.
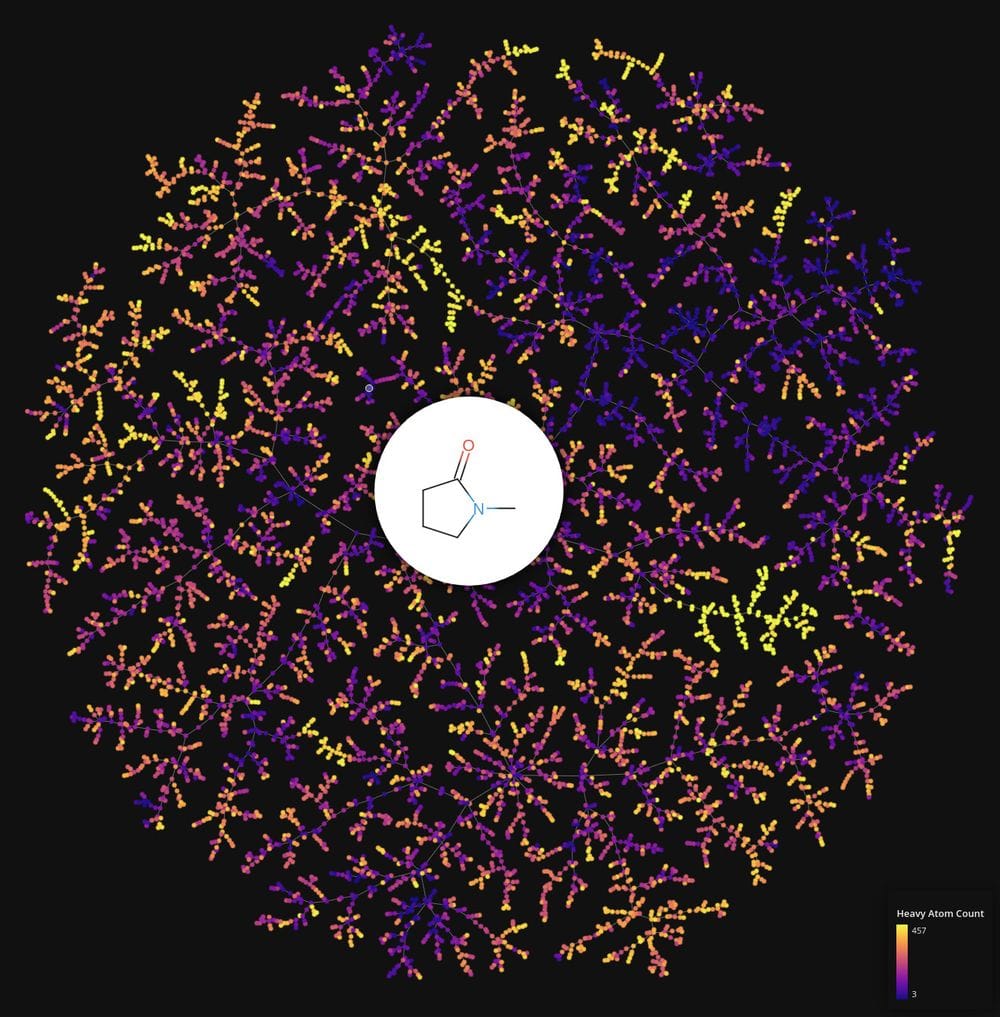
Here, we introduce a new data visualization and exploration method, TMAP (tree-map), which exploits locality sensitive hashing, Kruskal’s minimum-spanning-tree algorithm, and a multilevel multipole-based graph layout algorithm to represent large and high dimensional data sets as a tree structure, which is readily understandable and explorable. Compared to other data visualization methods such as t-SNE or UMAP, TMAP increases the size of data sets that can be visualized due to its significantly lower memory requirements and running time and should find broad applicability in the age of big data. We exemplify TMAP in the area of cheminformatics with interactive maps for 1.16 million drug-like molecules from ChEMBL, 10.1 million small molecule fragments from FDB17, and 131 thousand 3D-structures of biomolecules from the PDB Databank, and to visualize data from literature (GUTENBERG data set), cancer biology (PANSCAN data set) and particle physics (MiniBooNE data set). TMAP is available as a Python package. Installation, usage instructions and application examples can be found here.
Author(s): Daniel Probst, Jean-Louis Reymond